XPath语法在简数采集器中是定位获取页面HTML标签或者标签中的内容。(需要懂点HTML代码知识,重点看第4和第5章)
1. /--选择对应的子标签
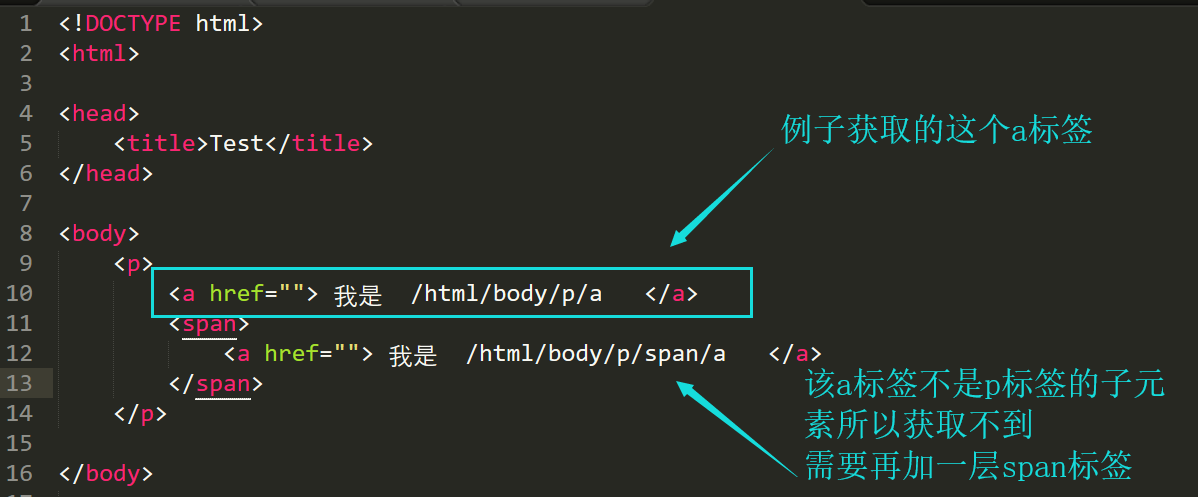
例子:/html/body/p/a
上面xpath路径意思是获取html标签下的子标签body,body下的子标签p,p下的子标签a,获取结果是对应下图的第10行a标签;
2. // --选择对应的子孙标签,即不考虑嵌套位置
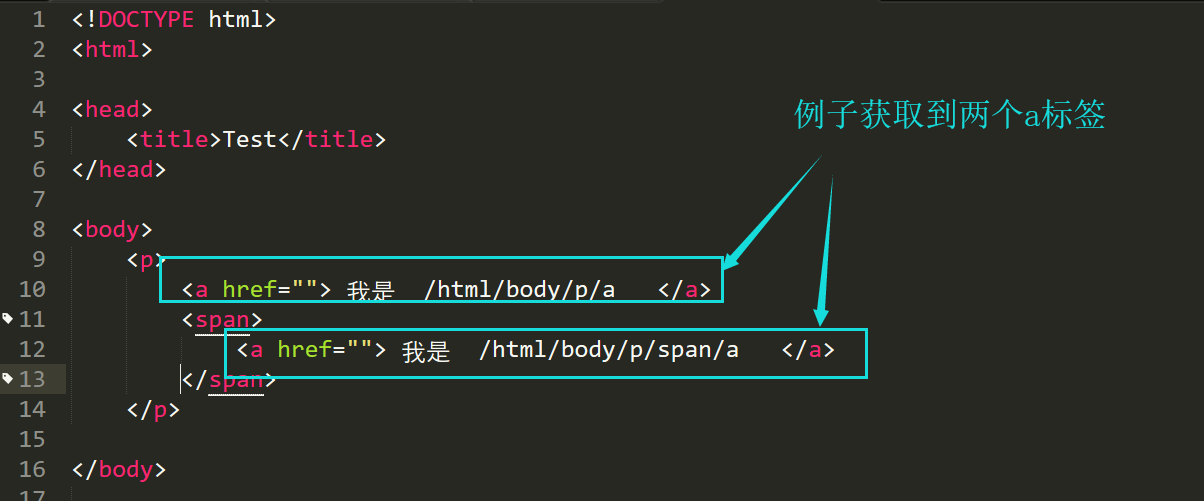
例子:/html/body/p//a
上面xpath路径意思是获取html标签下的子标签body,body下的子标签p,p下的所有标签a,获取结果是对应下图的第10行和12行的a标签;
3. [数字]--选取第几个标签
例子:/html/body/p/a[2]
上面xpath路径意思是获取html标签下的子标签body,body下的子标签p,p下的第二个标签a,获取结果是对应下图的第11行的a标签;

4. //*[@属性="值"]--选取属性对应的标签(重点)
@后面常填写id或者class属性,若能在页面找到对应的id属性更好,因为id属性在页面是唯一的值,即一个id值只能出现一次;
例子://*[@id="main"]
上面xpath路径意思是获取页面中id属性值为main的标签,不管嵌套关系了,直接定位到对应属性值的标签,十分快捷方便,获取结果是对应下图的第14行的a标签;

如果不用属性来定位,就得写成 /html/body/div/p/a ;
5. 在简数采集器为例:
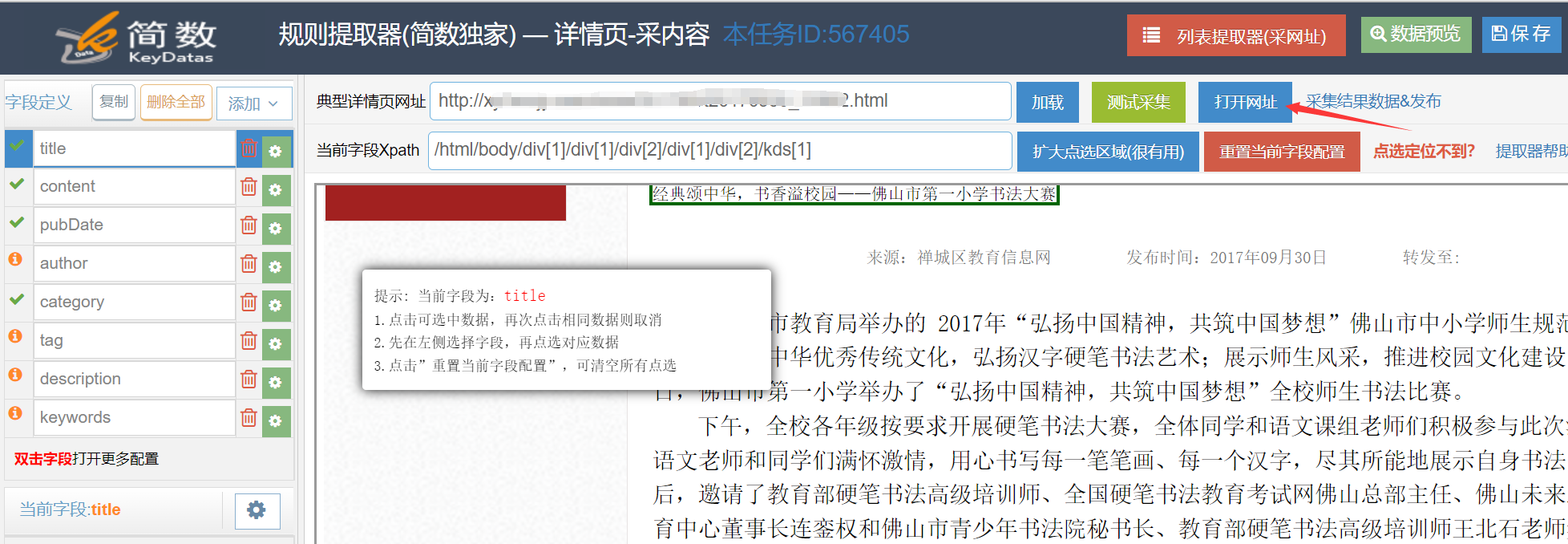
I、打开详情提起器,点击【打开网页】
II、打开查看html代码界面
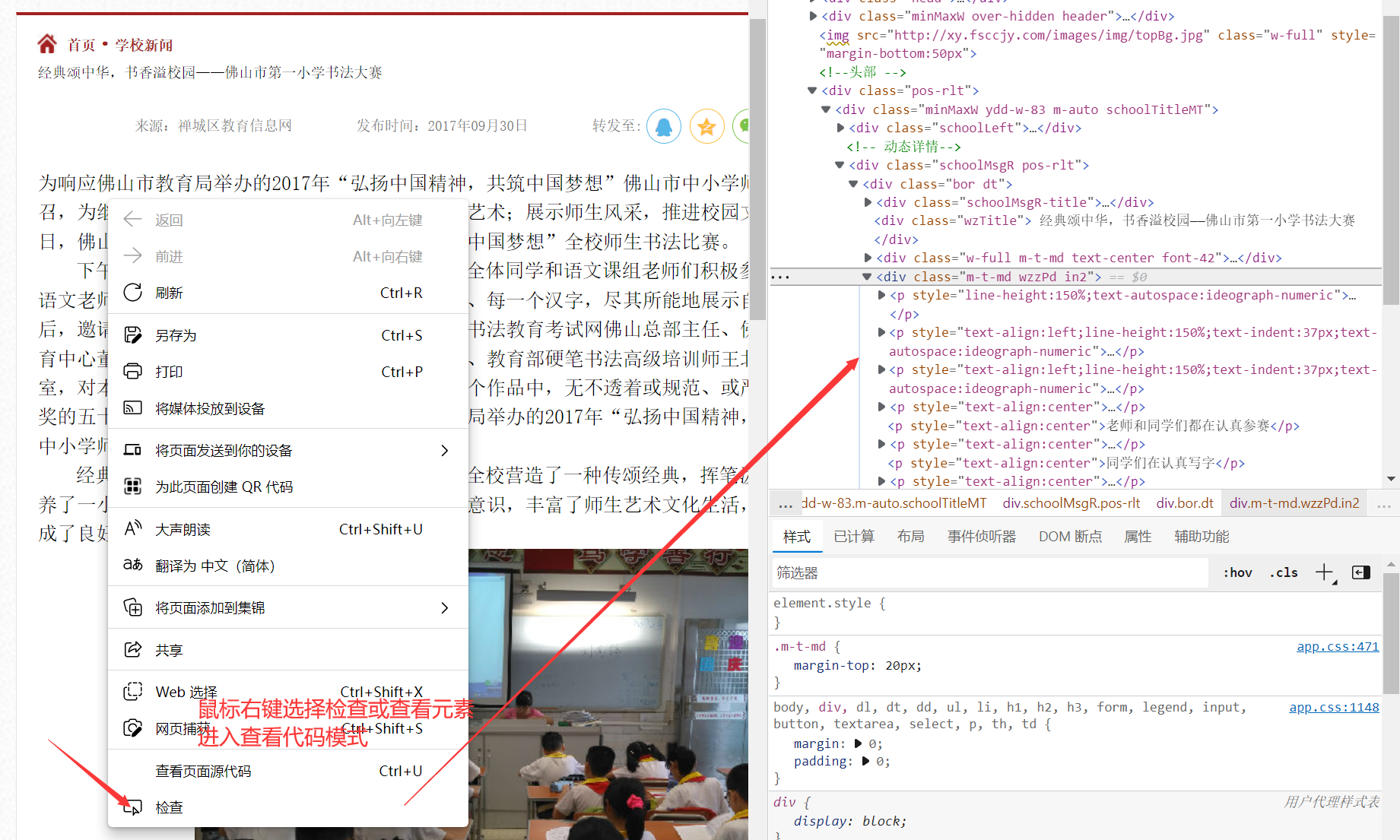
III、查找有没对应正文的特殊属性,找到class="m-t-md wzzPd in2"
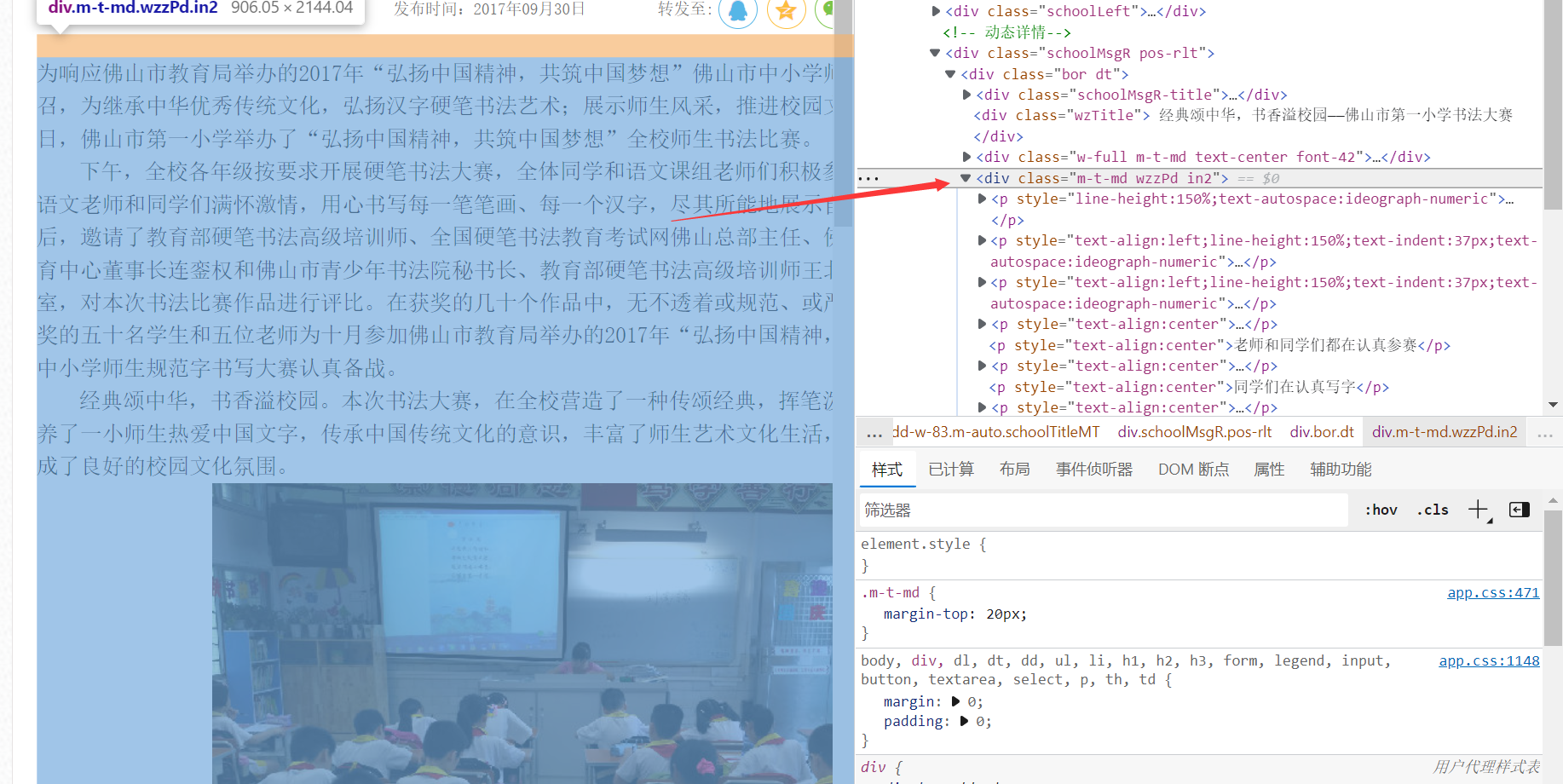
IV、填写到xpath路径中
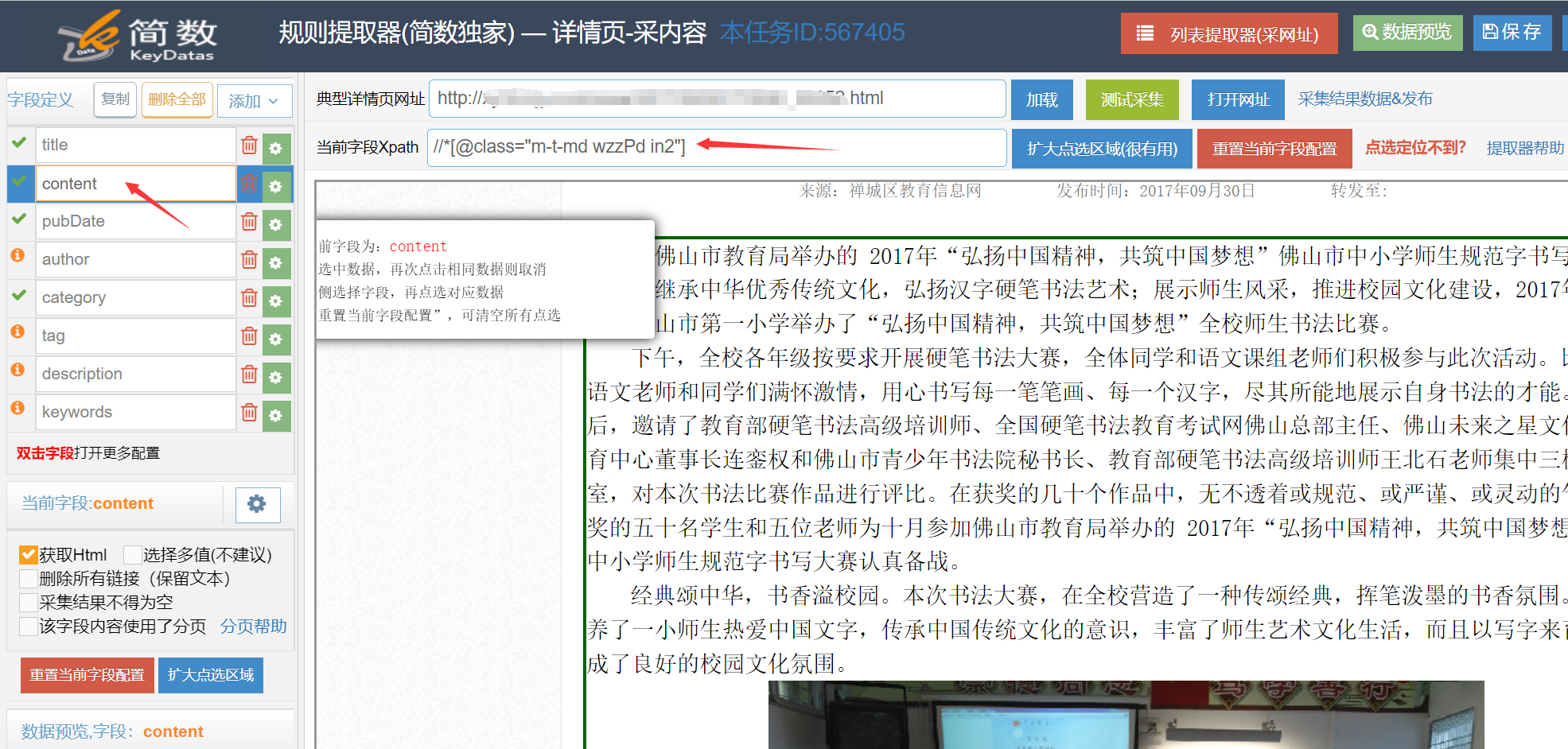
大部分爬虫都是使用xpath作为规则提取,属于通用规则,市面大部分采集器都支持xpath。